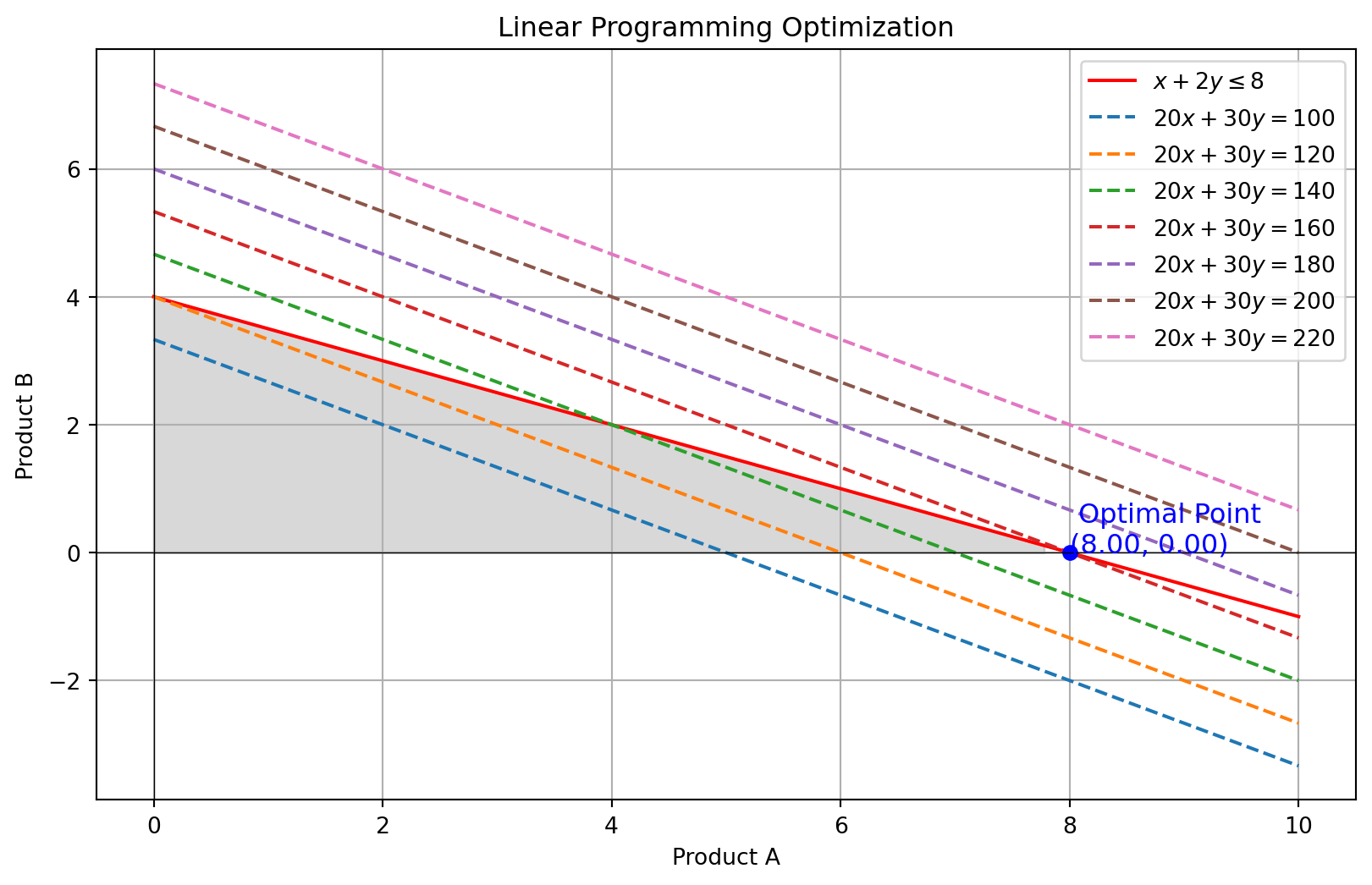
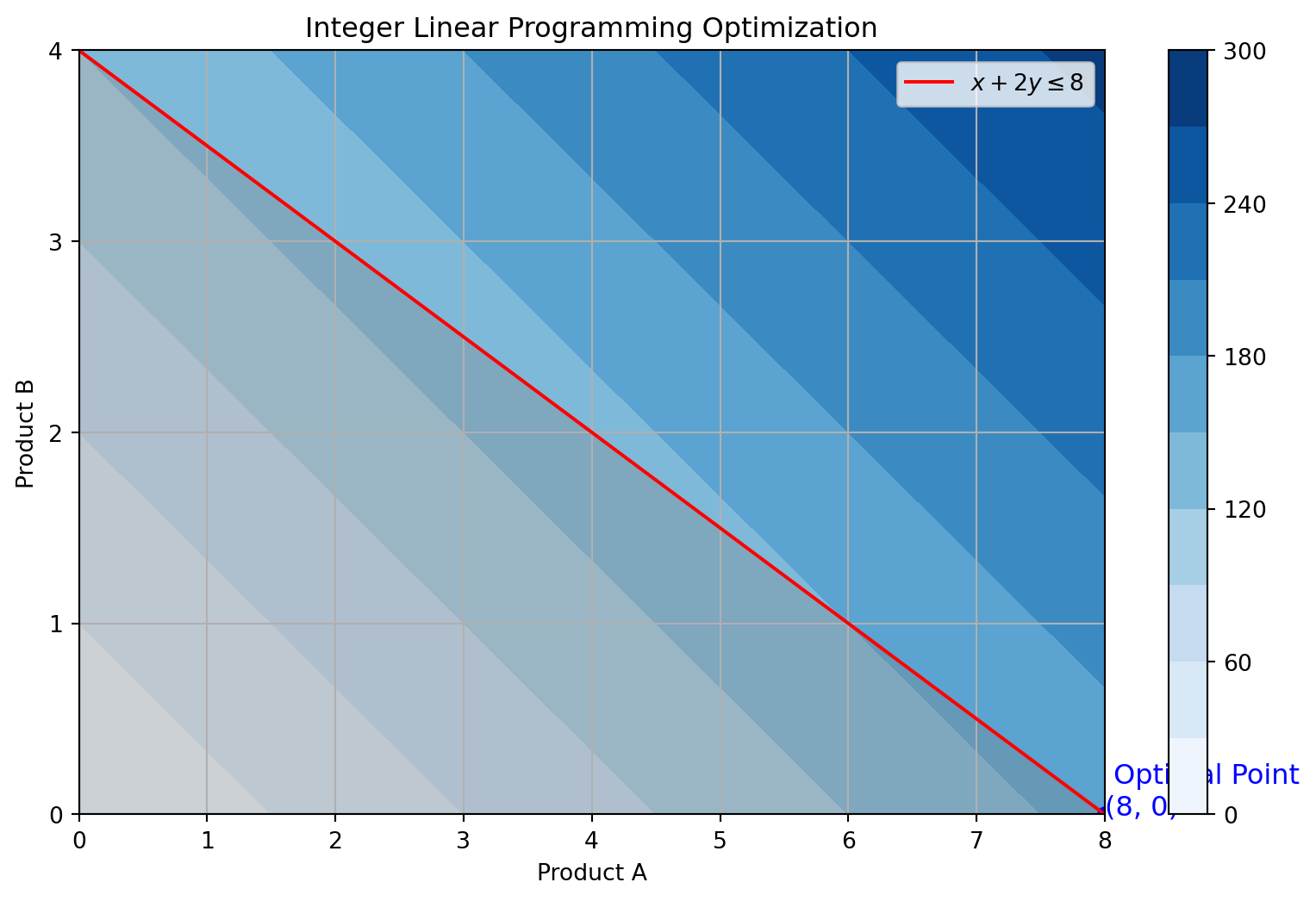
之前的例子没有考虑到 Product A 和 Product B 的取值需要是非负整数。如果我们要在这个条件下进行优化,就需要进行整数规划。在这种情况下,我们需要使用混合整数线性规划(Mixed-Integer Linear Programming, MILP)来求解。
使用 Gurobipy 库可以解决这个问题。
Note
安装 Gurobipy
conda install -c gurobi gurobi
import numpy as npimport matplotlib.pyplot as pltfrom gurobipy import Model, GRB# 创建模型model = Model()# 添加变量x = model.addVar(vtype=GRB.INTEGER, name="x") # Product Ay = model.addVar(vtype=GRB.INTEGER, name="y") # Product B# 设置目标函数:最大化利润model.setObjective(20* x +30* y, GRB.MAXIMIZE)# 添加约束:时间限制model.addConstr(x +2* y <=8, 'time_limit')# 优化模型model.optimize()# 提取结果optimal_value = model.objValoptimal_x = [v.x for v in model.getVars()]# 打印结果for v in model.getVars():print(f'{v.VarName}: {v.x}')print(f'Optimal value: {optimal_value}')# 画图x_vals = np.arange(0, 9, 1) # Product A 的整数取值范围y_vals = np.arange(0, 5, 1) # Product B 的整数取值范围X, Y = np.meshgrid(x_vals, y_vals)Z =20* X +30* Y # 目标函数plt.figure(figsize=(10, 6))contour = plt.contourf(X, Y, Z, levels=10, cmap='Blues')plt.colorbar(contour)plt.plot(optimal_x[0], optimal_x[1], 'bo') # 最优点plt.text(optimal_x[0], optimal_x[1], f' Optimal Point\n({int(optimal_x[0])}, {int(optimal_x[1])})', fontsize=12, color='blue')# 绘制约束线和可行域plt.plot(x_vals, (8- x_vals) /2, label=r'$x + 2y \leq 8$', color='red', linestyle='-')plt.fill_between(x_vals, 0, (8- x_vals) /2, where=(8- x_vals) /2>=0, color='gray', alpha=0.3)# 设置Y轴整数刻度plt.yticks(np.arange(0, max(y_vals)+1, 1)) # 设置Y轴仅显示整数刻度# 添加图表元素plt.xlabel('Product A')plt.ylabel('Product B')plt.title('Integer Linear Programming Optimization')plt.legend(loc='upper right')plt.grid(True)plt.show()
Set parameter Username
Academic license - for non-commercial use only - expires 2025-04-02
Gurobi Optimizer version 11.0.2 build v11.0.2rc0 (mac64[arm] - Darwin 24.1.0 24B83)
CPU model: Apple M3 Pro
Thread count: 12 physical cores, 12 logical processors, using up to 12 threads
Optimize a model with 1 rows, 2 columns and 2 nonzeros
Model fingerprint: 0xd214e7d0
Variable types: 0 continuous, 2 integer (0 binary)
Coefficient statistics:
Matrix range [1e+00, 2e+00]
Objective range [2e+01, 3e+01]
Bounds range [0e+00, 0e+00]
RHS range [8e+00, 8e+00]
Found heuristic solution: objective 160.0000000
Presolve removed 1 rows and 2 columns
Presolve time: 0.00s
Presolve: All rows and columns removed
Explored 0 nodes (0 simplex iterations) in 0.00 seconds (0.00 work units)
Thread count was 1 (of 12 available processors)
Solution count 1: 160
Optimal solution found (tolerance 1.00e-04)
Best objective 1.600000000000e+02, best bound 1.600000000000e+02, gap 0.0000%
x: 8.0
y: -0.0
Optimal value: 160.0
from gurobipy import Model, GRB# 创建模型model = Model()# 添加变量x = model.addVar(vtype=GRB.INTEGER, name="x") # 产品Ay = model.addVar(vtype=GRB.INTEGER, name="y") # 产品B# 设置目标函数:最大化利润model.setObjective(30* x +20* y, GRB.MAXIMIZE)# 添加约束model.addConstr(2* x + y <=40) # 机器1时间约束model.addConstr(x +2* y <=60) # 机器2时间约束# 优化模型model.optimize()# 提取结果for v in model.getVars():print(f'{v.VarName}: {v.x}')print(f'Optimal value: {model.objVal}')
Gurobi Optimizer version 11.0.2 build v11.0.2rc0 (mac64[arm] - Darwin 24.1.0 24B83)
CPU model: Apple M3 Pro
Thread count: 12 physical cores, 12 logical processors, using up to 12 threads
Optimize a model with 2 rows, 2 columns and 4 nonzeros
Model fingerprint: 0x8826119c
Variable types: 0 continuous, 2 integer (0 binary)
Coefficient statistics:
Matrix range [1e+00, 2e+00]
Objective range [2e+01, 3e+01]
Bounds range [0e+00, 0e+00]
RHS range [4e+01, 6e+01]
Found heuristic solution: objective 600.0000000
Presolve time: 0.00s
Presolved: 2 rows, 2 columns, 4 nonzeros
Variable types: 0 continuous, 2 integer (0 binary)
Root relaxation: objective 7.333333e+02, 2 iterations, 0.00 seconds (0.00 work units)
Nodes | Current Node | Objective Bounds | Work
Expl Unexpl | Obj Depth IntInf | Incumbent BestBd Gap | It/Node Time
0 0 733.33333 0 2 600.00000 733.33333 22.2% - 0s
H 0 0 730.0000000 733.33333 0.46% - 0s
0 0 733.33333 0 2 730.00000 733.33333 0.46% - 0s
Explored 1 nodes (2 simplex iterations) in 0.00 seconds (0.00 work units)
Thread count was 12 (of 12 available processors)
Solution count 2: 730 600
Optimal solution found (tolerance 1.00e-04)
Best objective 7.300000000000e+02, best bound 7.300000000000e+02, gap 0.0000%
x: 7.0
y: 26.0
Optimal value: 730.0
在这个实例中,MIP 帮助我们找到最大化利润的最佳生产数量。
16.3.2 交通流量优化问题实例
假设一个城市的交通网络如下图所示,每条边(道路)上标出的是该路段的道路容量(即最多允许通过的车辆数)。我们的目标是从源节点 S 到目标节点 T 的流量最大化。
graph TD
S -->|4| A
S -->|5| B
A -->|3| C
A -->|2| D
B -->|3| D
B -->|4| E
C --->|3| T
D --->|2| T
E -->|2| F
F -->|3| T
路径上的数值表示该路径的最大容量,例如 S → A = 4 指 S 点到 A 点最大流量为 4.
下面是使用 Gurobi 进行交通流量优化建模和求解的代码。
from gurobipy import Model, GRB# 创建模型model = Model("MaxFlow")# 边及其容量edges = {'S': {'A': 4, 'B': 5},'A': {'C': 3, 'D': 2},'B': {'D': 3, 'E': 4},'C': {'T': 3},'D': {'T': 2},'E': {'F': 2},'F': {'T': 3}}# 添加变量flows = {}for u in edges:for v in edges[u]: flows[u, v] = model.addVar(name=f"flow_{u}_{v}", ub=edges[u][v])# 设置目标函数:最大化从 S 到 T 的流量model.setObjective(sum(flows['S', v] for v in edges['S']), GRB.MAXIMIZE)# 添加节点平衡约束# 所有中间节点的流量平衡:输入等于输出nodes =set(edges.keys()).union({v for u in edges for v in edges[u]})for node in nodes:if node notin ['S', 'T']: inflow =sum(flows[u, node] for u in edges if (u, node) in flows) outflow =sum(flows[node, v] for v in edges[node]) if node in edges else0 model.addConstr(inflow == outflow, name=f"node_{node}_balance")# 优化模型model.optimize()# 打印结果if model.status == GRB.OPTIMAL:print('\nOptimal flow value: ', model.objVal)for (u, v), flow_var in flows.items():print(f"{u} -> {v}: {flow_var.x}")
Gurobi Optimizer version 11.0.2 build v11.0.2rc0 (mac64[arm] - Darwin 24.1.0 24B83)
CPU model: Apple M3 Pro
Thread count: 12 physical cores, 12 logical processors, using up to 12 threads
Optimize a model with 6 rows, 10 columns and 15 nonzeros
Model fingerprint: 0xcaf27f06
Coefficient statistics:
Matrix range [1e+00, 1e+00]
Objective range [1e+00, 1e+00]
Bounds range [2e+00, 5e+00]
RHS range [0e+00, 0e+00]
Presolve removed 6 rows and 10 columns
Presolve time: 0.00s
Presolve: All rows and columns removed
Iteration Objective Primal Inf. Dual Inf. Time
0 7.0000000e+00 0.000000e+00 0.000000e+00 0s
Solved in 0 iterations and 0.00 seconds (0.00 work units)
Optimal objective 7.000000000e+00
Optimal flow value: 7.0
S -> A: 3.0
S -> B: 4.0
A -> C: 3.0
A -> D: 0.0
B -> D: 2.0
B -> E: 2.0
C -> T: 3.0
D -> T: 2.0
E -> F: 2.0
F -> T: 2.0
16.3.2.1 模型和变量
模型:创建一个名为 “MaxFlow” 的模型。
变量:定义每条边上的流量,变量的上限(ub)设为边的容量。例如 flow_S_A 表示从 S 到 A 的流量,它的上限为 4。
16.3.2.2 目标函数
目标函数:设置要最大化 S 的总出流量,即从 S 到所有邻接节点(即 S → A 和 S → B)的流量之和。
16.3.2.3 约束条件
节点平衡约束:对所有中间节点,流入流量等于流出流量。
对于每个节点,除了源节点和目标节点之外,输入流量必须等于输出流量。例如,对节点 A 的约束是 flow_S_A == flow_A_C + flow_A_D。
该约束条件确保流量在整个网络中保持平衡,没有无中生有的流量,也没有流量消失。
节点 S 和 T 将没有这一平衡约束,因为 S 是源点,而 T 是目的点。
16.3.2.4 结果
求解模型:调用 model.optimize() 来求解最大流量问题。
输出结果:打印最优流量值和每条边上的流量值。
各条路径上的流量如下图所示,最大的流量即为 7。
graph TD
S -->|3| A
S -->|4| B
A -->|3| C
A .->|0| D
B -->|2| D
B -->|2| E
C --->|3| T
D --->|2| T
E -->|2| F
F -->|2| T
from gurobipy import Model, GRB# 创建模型model = Model()# 添加变量x = model.addVar(vtype=GRB.CONTINUOUS, name="x")y = model.addVar(vtype=GRB.INTEGER, name="y")# 设置目标函数model.setObjective(2* x +3* y, GRB.MINIMIZE)# 添加约束model.addConstr(x + y >=10, "c0")model.addConstr(3* x +2* y <=25, "c1")# 优化模型model.optimize()# 输出结果for v in model.getVars():print(f'{v.varName}: {v.x}')print(f'Objective: {model.objVal}')
Gurobi Optimizer version 11.0.2 build v11.0.2rc0 (mac64[arm] - Darwin 24.1.0 24B83)
CPU model: Apple M3 Pro
Thread count: 12 physical cores, 12 logical processors, using up to 12 threads
Optimize a model with 2 rows, 2 columns and 4 nonzeros
Model fingerprint: 0x6e3d58b8
Variable types: 1 continuous, 1 integer (0 binary)
Coefficient statistics:
Matrix range [1e+00, 3e+00]
Objective range [2e+00, 3e+00]
Bounds range [0e+00, 0e+00]
RHS range [1e+01, 2e+01]
Presolve removed 2 rows and 2 columns
Presolve time: 0.00s
Presolve: All rows and columns removed
Explored 0 nodes (0 simplex iterations) in 0.00 seconds (0.00 work units)
Thread count was 1 (of 12 available processors)
Solution count 1: 25
Optimal solution found (tolerance 1.00e-04)
Best objective 2.500000000000e+01, best bound 2.500000000000e+01, gap 0.0000%
x: 5.0
y: 5.0
Objective: 25.0